
C言語によらず、対話的なプログラムなどでは 一行分の入力を受付けて、それを処理することがよくあります。
ただ、C言語で1行の入力を行うとたまに困った現象が発生します。 例えば
- 入力中に文字を挿入しようと無意識にカーソルキーを触ってしまい~]]D などエスケープな文字を出してしまう
- 入力用バッファの長さが固定なので無駄にバッファサイズを大きめに決めなければならない
などなどです。
こういった時、編集可能な任意の長さの一行分入力を待ち受けるルーチンが欲しかったりします。 このような場合は readlineやeditline を使う方法が考えられますが、 ライブラリが使えない場合やちょっとしたプログラムにそこまで高級な入力管理がいらない場合 自作のちょっとした入力ルーチンがあると便利です。 あとは、大体興味の問題です…。
{c:red}ソースコードは記事末尾に掲載しています{/c}
仕様
- 任意長の文字列を入力できる
- カーソルキーで行ったり来たりして文字の挿入や削除の編集ができる
- UTF8な日本語の1文字をちゃんと識別する。
- パスワードなど入力するときに文字の代わりにマスクを表示できる
収録関数
- char *umampt(char *prompt); 1行入力プロンプト
- char *umampt_pw(char *prompt); 1行パスワード入力プロンプト
- char *umampt_mask(char *prompt, unsigned char mask); 指定マスクで1行パスワード
- void umampt_free(char *addr); 入力文字列開放
使用例
#include <stdio.h>
#include "umampt.h"
int main()
{
char *line;
line = umampt_pw("pass>");
printf("%s\n",line);
umampt_free(line);
return 0;
}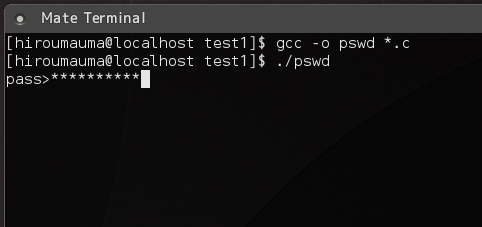
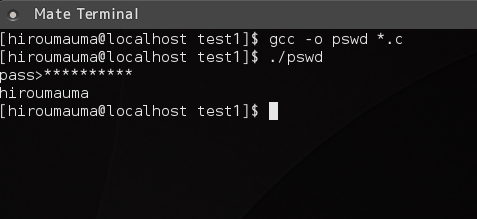
簡単にパスワード入力が作れます。 umampt_mask(char *prompt, -1); とマスクに -1 を指定するとなにも表示されなくなります。 つまり sudo などでパスワードを入力するときのように パスワード入力中カーソルは一切動きません。
#include "umampt.h"
#include <stdio.h>
int main()
{
char *line;
for(;;)
{
line = umampt(">");
if(line==NULL) break;
printf("%s\n",line);
umampt_free(line);
}
return 0;
}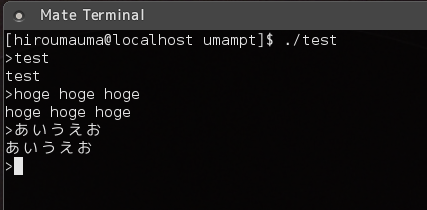
こうすると対話式プログラム風のものがすぐにできます。
以下解説
UTF8文字列の取り扱いについて
一番やっかいなのがCで日本語(UTF8)を取り扱うことです。 UTF-8は 1〜4(6)バイトのいろいろな長さのコードが混在するので 不用意に カーソルを移動してバッファを1バイトずつずらして入力 などしてしまうと大変なことになります。(後述)
基本の仕組み
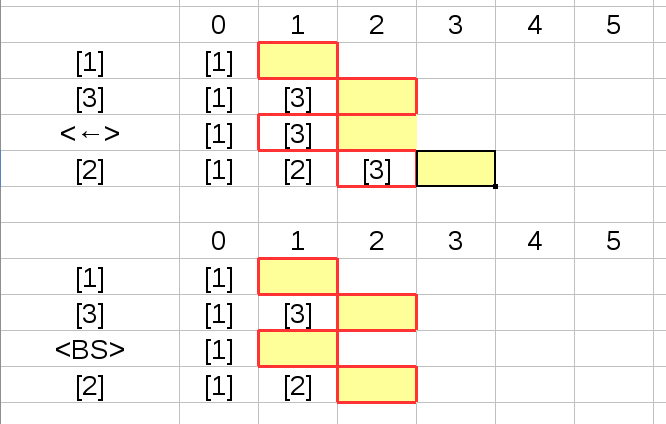
基本的な方法はそんなに難しくありません。 以前のReturnなしで1文字入力する 手法を利用して1文字ずつ データを読み出しbufferに並べていきます。 この時 バッファーの入力位置を記録する cur と 文字列の末尾を記録する tail の2つを利用して文字列を管理します。 文字が入力されると buffer[cur] にその文字を挿入して cur と tail とそれぞれ +1 するだけです。
例えば
[1] [3] [2] を入力した場合

このように バッファには [1][3][2] と並びます。 一番左の行が入力された順番 そして 右がその時の バッファの様子を表しています。
カーソルキーやバックスペースが入力された場合は cur,tail を以下のように減らしたり増やしたりすれば 意図したようにバッファーの配列が編集されます。
ただし、これは1文字1byteの場合です。 例えば 3バイトの文字が混ざり [1][3][ABC] を入力してから バックスペースを 入力してしまうと
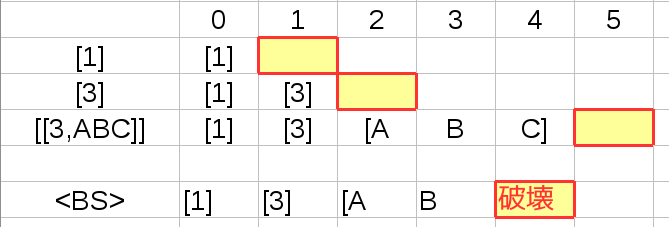
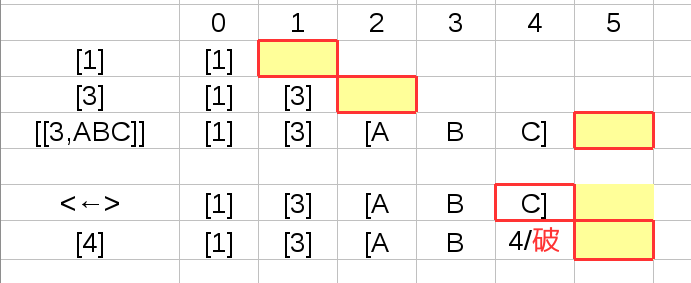
このように3バイト文字の末尾1文字部分を侵食してしまい
さらに入力を続けるとその文字が壊れてしまいます。
実際に単純な方法で実装して日本語を入れてみました。 以下の例では a b c あ ← 4 と入力していますが
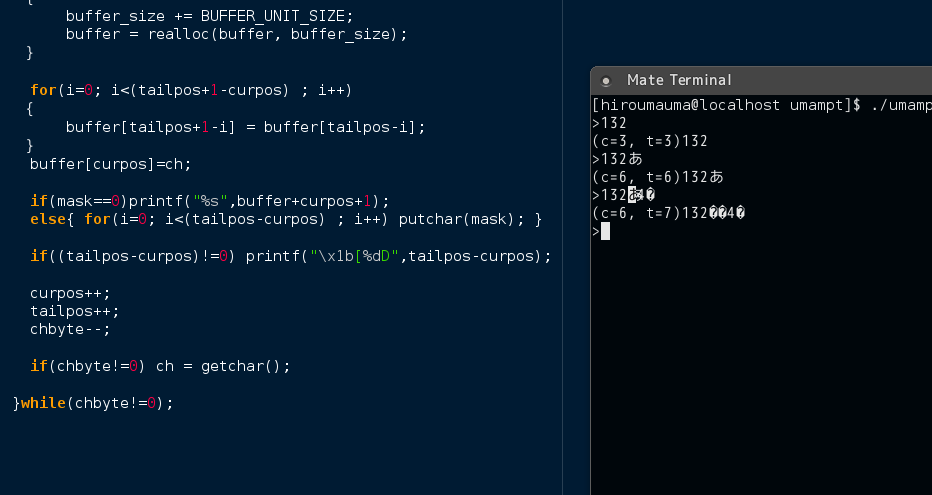
このように あ の一部が割れて 3バイトが 2バイトと1バイトに分かれて 4が割り込み 大変なことになっているのがわかります。
これをうまくするために
static const char utf8_bytes[256] = {
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,
1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,
1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,
3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,4,4,4,4,4,0,0,0,0,0,0,0,0,0,0,0
};
#define utf8_nextch(X) (char *)((X) + utf8_bytes[*(unsigned char *)(X)])これを使います。 テーブルは前回の記事で作ったものです。 このテーブルの便利さは 実は今回こそ その真価を発揮します。
それがその下の #define utf8_nextch(X) の部分です。
これは あるUTF8の文字列へのポインタを与えるとその文字列中に次の2番目の文字の先頭へのポインタを返す
すぐれものです。 例えば現在の "カーソルより前にある文字の個数" がわかっている場合 それを n とすると
p = buffer;
for(i=0; i<(n-1) ; i++) p = utf8_nextch(p);こんなかんじで直前の文字の先頭へのポインタを得ることができます。
この技を駆使することで UTF8が混ざった文字列でも 文字数のカウントやコピー削除 といった必要な処理が簡単に記述できます。
ちょっとした問題
バッファーの編集はそれでいいとしてちょっと問題なのが表示関連です。 というのは UTF8の3バイト文字の場合
文字数は1文字 バッファ上では3バイト 表示上は全角でカーソル幅2つ分
を消費します。1文字1バイト1カーソル幅のASCII文字に対してなんとも面倒ですが これらは別に管理しないと編集中にどんどん バッファー上のデータと表示が崩れてしまいます。
umampt.c
以上を踏まえてできたのが umampt.c です。全体で300行ほどの小さなソースです。
ソースコード
以下 umampt.c の全文です。
/*
: hiroumauma
: show prompt
*/
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <termios.h>
#include <unistd.h>
#include <sys/ioctl.h>
#define TERM_RAW_ON 1
#define TERM_RAW_OFF 0
int termraw(int flag)
{
static struct termios t_save;
struct termios t;
if( flag == 1 )
{
if( tcgetattr(0,&t) == -1 ) return -1;
t_save = t;
t.c_iflag = ~( BRKINT | ISTRIP | IXON );
t.c_lflag = ~( ICANON | IEXTEN | ECHO | ECHOE | ECHOK | ECHONL );
t.c_cc[VMIN] = 1;
t.c_cc[VTIME] = 0;
if( tcsetattr(0, TCSANOW, &t) == -1 ) return -1;
return 0;
}else{
if( tcsetattr(0, TCSANOW, &t_save) == -1 ) return -1;
return 0;
}
}
static const char utf8_bytes[256] = {
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,
1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,
1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,
3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,4,4,4,4,4,0,0,0,0,0,0,0,0,0,0,0
};
#define utf8_nextch(X) (char *)((X) + utf8_bytes[*(unsigned char *)(X)])
#define ESCAPE (1<<1)
#define CTRL_C (1<<2)
#define RETURN (1<<3)
#define DELETE (1<<4)
#define TAB (1<<5)
#define KEY_RIGHT (1<<6)
#define KEY_LEFT (1<<7)
#define FLAG_ON(F,X) ((F) |= (X))
#define FLAG_CHECK(F,X) ((F) & (X))
#define BUFFER_UNIT_SIZE 64
#define NOECHO 1
#define NOMASK 0
char *vumampt(char *prompt, unsigned char mask)
{
unsigned char ch;
unsigned char flags;
unsigned char chbyte;
int i,d,r1,r2,c,s,t;
int bytes;
int tailpos;
int curpos;
int showpos;
int nocbcr;
int length;
int buffer_size;
char *buffer;
char *p;
struct winsize ws;
ioctl( STDOUT_FILENO, TIOCGWINSZ, &ws );
termraw(TERM_RAW_ON);
setbuf(stdout, NULL);
buffer_size = BUFFER_UNIT_SIZE;
buffer = calloc(buffer_size, sizeof(char));
if(buffer==NULL) return NULL;
nocbcr = 0;
curpos = 0;
showpos = 0;
tailpos = 0;
length = 0;
printf("%s",prompt);
for(;;)
{
flags = 0x0;
ch = getchar();
chbyte = utf8_bytes[ch];
switch(ch)
{
case 0x03: FLAG_ON( flags, CTRL_C ); break;
case 0x0d: FLAG_ON( flags, RETURN ); break;
case 0x09: FLAG_ON( flags, TAB ); break;
case 0x1b: FLAG_ON( flags, ESCAPE ); break;
case 0x7f: FLAG_ON( flags, DELETE ); break;
}
if(FLAG_CHECK( flags, ESCAPE ))
{
ch = getchar();
if(ch==0x5b)
{
ch = getchar();
switch(ch)
{
case 0x33: ch = getchar();
FLAG_ON( flags, DELETE ); break;
case 0x43: FLAG_ON( flags, KEY_RIGHT ); break;
case 0x44: FLAG_ON( flags, KEY_LEFT ); break;
}
}
}
if(FLAG_CHECK( flags, CTRL_C ))
{
termraw(TERM_RAW_OFF);
free(buffer);
putchar('\n');
return NULL;
}
if( FLAG_CHECK( flags, KEY_RIGHT ) && curpos<tailpos )
{
p = buffer;
for(i=0; i<(nocbcr+1) ; i++) p = utf8_nextch(p);
d = (int)((unsigned long)p -(unsigned long)buffer);
if((d-curpos)>=1) showpos++;
if((d-curpos)> 1) showpos++;
curpos = d;
nocbcr++;
}
if( FLAG_CHECK( flags, KEY_LEFT ) && curpos>0 )
{
p = buffer;
for(i=0; i<(nocbcr-1) ; i++) p = utf8_nextch(p);
d = (int)((unsigned long)p -(unsigned long)buffer);
if((curpos-d)>=1) showpos--;
if((curpos-d)> 1) showpos--;
curpos = d;
nocbcr--;
}
if(FLAG_CHECK( flags, DELETE ) && curpos>0 )
{
p = buffer;
for(i=0; i<(nocbcr-1) ; i++) p = utf8_nextch(p);
d = (int)((unsigned long)p -(unsigned long)buffer);
for(i=0; i<(tailpos+1-curpos) ; i++)
{
buffer[d+i] = buffer[curpos+i];
}
if((curpos-d)>=1){ showpos--; length--; }
if((curpos-d)> 1){ showpos--; length--; }
tailpos -= curpos-d;
curpos = d;
nocbcr--;
}
if(FLAG_CHECK( flags, RETURN))
{
buffer[tailpos] = '\0';
putchar('\n');
break;
}
if( flags==0 )
{
if(chbyte != 0) nocbcr++;
if(chbyte >= 1){ length++; showpos++;}
if(chbyte > 1){ length++; showpos++;}
if(chbyte != 0)do
{
if(tailpos+1 >= buffer_size)
{
buffer_size += BUFFER_UNIT_SIZE;
buffer = realloc(buffer, buffer_size);
}
for(i=0; i<(tailpos+1-curpos) ; i++)
{
buffer[tailpos+1-i] = buffer[tailpos-i];
}
buffer[curpos]=ch;
curpos++;
tailpos++;
chbyte--;
if(chbyte!=0) ch = getchar();
}while(chbyte!=0);
}
if(mask==NOECHO) continue;
r1 = (showpos +strlen(prompt)-1)/(ws.ws_col);
r2 = (length +strlen(prompt)-1)/(ws.ws_col);
c = (showpos +strlen(prompt) )/(ws.ws_col);
s = (showpos +strlen(prompt) )%(ws.ws_col);
t = (length +strlen(prompt) )%(ws.ws_col);
if( FLAG_CHECK( flags, KEY_LEFT )
|| FLAG_CHECK( flags, DELETE ) )
{
if( s == 0 ) r1++;
if( s == (ws.ws_col-1)) r1++;
}
if( FLAG_CHECK( flags, KEY_RIGHT ) )
{
if( s == 0 ) r1++;
if( s == (ws.ws_col-1)) r2--;
}
if( r1 != 0 ) printf("\x1b[%dA",r1);
if( mask == NOMASK)
{
printf("\r%s%s\x1b[K\r", prompt,buffer);
}else{
printf("\r%s", prompt);
for(i=0; i<length; i++) putchar(mask);
}
if( FLAG_CHECK( flags, DELETE )
&& t == 1
&& ((length+strlen(prompt))!= 1) ) putchar(0x20);
if( r2 != 0 ) printf("\x1b[%dA",r2);
putchar('\r');
if( c != 0 ) printf("\x1b[%dB",c);
if( s != 0 ) printf("\x1b[%dC",s);
if( FLAG_CHECK( flags, DELETE ) && s == 0) printf(" \b");
}
termraw(TERM_RAW_OFF);
return buffer;
}
char *umampt(char *prompt)
{
return vumampt(prompt, NOMASK);
}
char *umampt_pw(char *prompt)
{
return vumampt(prompt, '*');
}
char *umampt_mask(char *prompt, unsigned char mask)
{
if( utf8_bytes[mask] == 1 ) return vumampt(prompt, mask);
else return vumampt(prompt, NOECHO);
}
void umampt_free(char *addr)
{
free(addr);
return;
}
続いて umampt.h
#ifndef UMA_PROMPT_H
#define UMA_PROMPT_H 1
char *umampt(char *prompt);
char *umampt_pw(char *prompt);
char *umampt_mask(char *prompt, unsigned char mask);
void umampt_free(char *addr);
#endifテキストの編集なんていうのは、ふだんなんの疑いもなくやっていることなので 有り難みが湧きにくいですが、実際に考えてみると結構大変だなと実感しました。
ただ、UTF8の取り扱いなど得るものも多い実験でした。




