![[ksnctf] Are you human?](/images/2/2/e/d/c/22edcdfa601888fb8db662a9faf8cfb5e35e570e-34a.png "[ksnctf] Are you human?")
ksnctfにチャレンジ 第34問目です。
※ksnctfは常駐型のCTFサイトです。 ※問題のページはコチラです。
Are you human?
第一段階として 画像データとして渡される RS符号付きの破損画像データの ダンプデータを復元する作業に苦戦します。
OCRにかけるしかないのですが、OCRを邪魔する線などが多く OCRが嫌いそうな明るさの文字のせいでほとんどテキストが 抽出できません。
よってまず ImageMagicで下処理してみることにしました。
OCRには tesseract を使うことにして
#!/bin/sh
mkdir text
mkdir img
echo "tessedit_char_whitelist 0123456789ABCDEF" > ocr.conf
for pic in *.png
do
base=$(basename ${pic} .png)
BG=$(convert ${base}.png -crop 1x1+0+0 txt:- | sed -n 2p - | cut -d " " -f4)
convert -fill '#FFFFFF' -opaque "${BG}" ${base}.png ${base}_a.png
convert -threshold 55000 ${base}_a.png ${base}_b.png
convert -gaussian-blur 2x2 ${base}_b.png ${base}_c.png
convert -threshold 35000 ${base}_c.png ${base}_d.png
tesseract ${base}_d.png stdout -psm 7 ocr.conf > ./txt/${base}.txt
mv ${base}_d.png ./img/${base}.png
rm ${base}_?.png
doneこれで
 ↓
↓
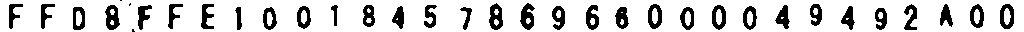 に
変換されるので 大抵の画像でOCRが通るようになりますが
それでも百近いデータを処理ミスしてしまい
これは手作業で直さないとどうにもなりそうになく、
ちょっとやる気にならないので画像の処理方法を工夫中です。
に
変換されるので 大抵の画像でOCRが通るようになりますが
それでも百近いデータを処理ミスしてしまい
これは手作業で直さないとどうにもなりそうになく、
ちょっとやる気にならないので画像の処理方法を工夫中です。
ある程度の読み取りミス (D↔0 や B↔8)などは リード・ソロモンの訂正能力を信じたいとしても 出力文字0の画像が数十あるようではちょっと厳しいと思います。
…というわけで未解決です。
仕組み上はこのOCR作業を乗り越えれば、 得られるテキストが Flagが書かれていると思われる画像にリードソロモン符号を 付したものにノイズがわざと加えられたデータのダンプ になっているので
ダンプテキストから元のバイナリに戻し リードソロモン符号をデコードすれば ノイズを修正して元の正確なデータが手に入る
という筋書きだと思います。
が、肝心のOCRが上手く行かないので続きができない感じです。
OCRが上手く行く方法に心当たりがある方 または、OCR失敗データを人力修正できる忍耐力のある方は是非 コメントください…。 リードソロモン符号のデコードに関しては
このあたりのコードが使えると思います。 配布されている問題ページで配布されている ecc.py 内での宣言から
N = 255 K = 64 GF 2^8bit
という設定にすればdecode可能なハズです。




